|
I'm a fourth year PhD student in the computer science department at Stanford University advised by Dorsa Sadigh. Currently, I am a research intern at Physical Intelligence. Previously, I was a student researcher in the Google Deepmind Robotics group and a recepient of the NDSEG Fellowship. I completed my undergrad at UC Berkeley where I worked with Professors Pieter Abbeel and Lerrel Pinto. |

|
|
I'm broadly interested in learning for decision making and robotics. Papers (and preprints) are ordered by recency. |

|
Vincent DeBakker Joey Hejna, Tyler Ga Wei Lum, Onur Celik, Aleksandar Taranovic, Denis Blessing, Gerhard Neumann, Jeannette Bohg, Dorsa Sadigh Arxiv Preprint paper / Website / code We use VLM generated plans to guide low-level RL for dexterous manipulation tasks. |

|
Joey Hejna, Suvir Mirchandani, Ashwin Balakrishna, Annie Xie, Ayzaan Wahid, Jonathan Tompson, Pannag Sanketi, Dhruv Shah, Coline Devin*, Dorsa Sadigh* RSS 2025 paper / website / code We introduce a new method for robot data curation that uses mutual information to select the most informative demonstrations. We show that this approach outperforms existing methods in both simulation and real-world settings. |

|
Jaden Clark, Joey Hejna, Dorsa Sadigh ICRA 2025 paper / website This paper introduces a novel approach that leverages priors generated by pre-trained LLMs alongside the precision of preference learning. Our method, termed Language-Guided Preference Learning (LGPL), uses LLMs to generate initial behavior samples, which are then refined through preference-based feedback to learn behaviors that closely align with human expectations. |

|
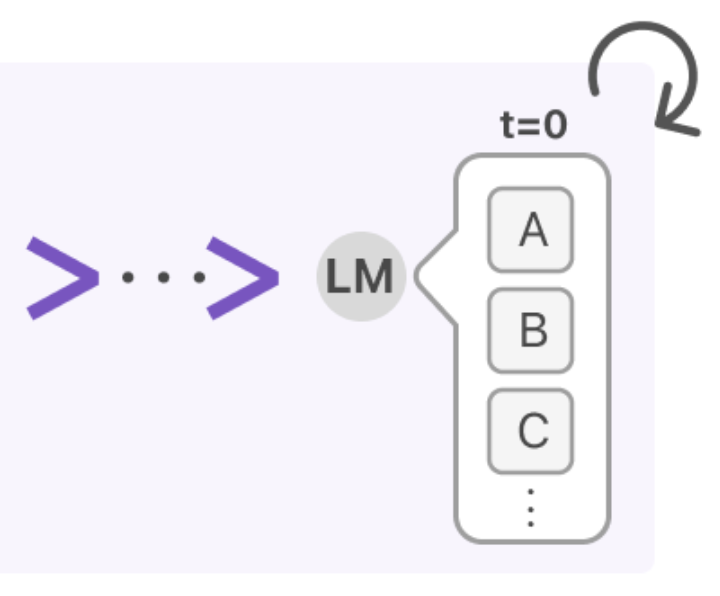
Jason Ma, Joey Hejna, ... Google Deepmind Robotics ... , Dorsa Sadigh, Fei Xia ICLR 2025 paper / website GVL poses value estimation as a temporal ordering problem over shuffled video frames; this seemingly more challenging task encourages VLMs to more fully exploit their underlying semantic and temporal grounding capabilities to differentiate frames based on their perceived task progress, consequently producing significantly better value predictions. |
|
Omar Shaikh*, Michelle Lam*, Joey Hejna*, Yijia Shao, Michael Bernstein, Diyi Yang ICLR 2025 paper / code We introduce DITTO, an algorithm for few-shot adaptation or alignment of large language models using only two or three human demonstrations. We show that DITTO outperforms prior methods by a significant margin on automated evals and a real-world users study. |

|
Joey Hejna, Chethan Bhateja, Yichen Jiang, Karl Pertsch, Dorsa Sadigh CoRL 2024 (Best Paper Nominee, top 6 of 671) paper / code We introduce ReMix, a recipe for automatically curating data mixtures for training large scale robotic imitation learning policies. We demonstrate improvements over human-curated and uniform dataset mixtures. |
|
Suvir Mirchandani, Suneel Belkhale, Joey Hejna, Evelyn Choi, Md Sazzad Islam, Dorsa Sadigh CoRL 2024 paper We investigate how well success-filtered autonomous imitation can work in real-world robotics settings. |

|
Minyoung Hwnag, Joey Hejna, Dorsa Sadigh, Yonatan Bisk IEEE RA-L project page / paper Evaluating robot motions involves more than just the start and end states; it's about how the task is performed. We propose motion instruction fine-tuning (MotIF) and MotIF-1K dataset to improve VLMs' ability to understand nuanced robotic motions. |
|
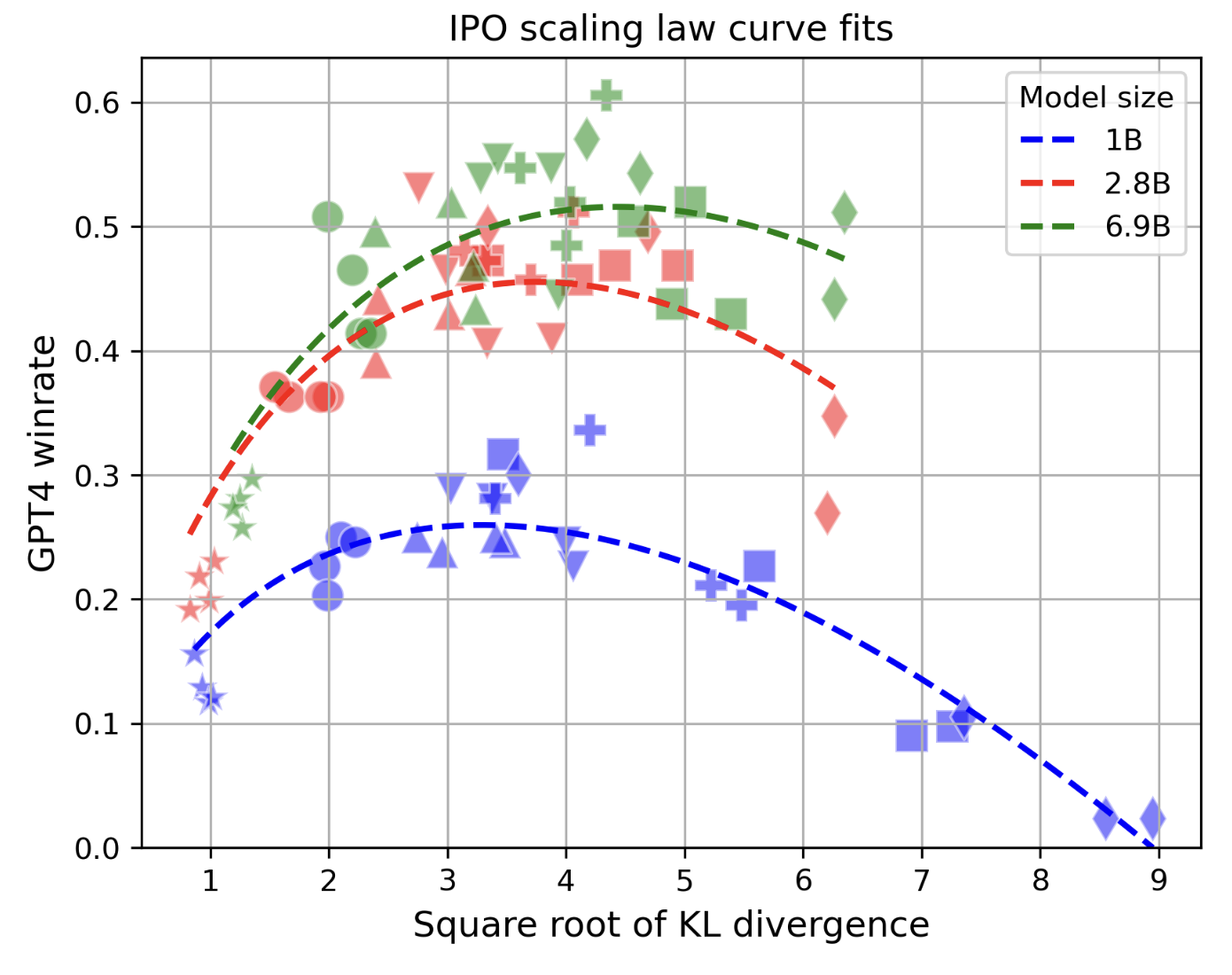
Rafael Rafailov*, Yashwanth Chittepu*, Ryan Park*, Harshit Sikchi*, Joey Hejna, W. Bradley Knox, Chelsea Finn, Scott Niekum ArXiv Pre-print paper Through extensive experimentation and multiple model scales we characterize the over-optimization problem for direct alignment algorithms in large langauge models. |

|
Alexander Khazatsky*, Karl Pertsch*, ..., Joey Hejna, ..., Sergey Levine, Chelsea Finn RSS 2024 website / paper / code A large diverse dataset collected across multiple institutions totalling over 75K robot trajectories. |
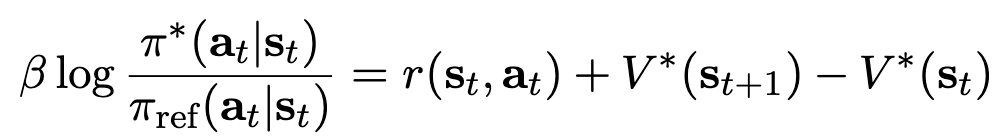
|
Rafael Rafailov*, Joey Hejna, Ryan Park, Chelsea Finn ArXiv Pre-print paper Understanding direct alignment algorithms for LLMs through the perspective of a per-token Markov Decision Process. |

|
Dibya Ghosh*, Homer Walke, Karl Pertsch*, Kevin Black*, Sudeep Dasari, Joey Hejna, Charles Xu, Jianlan Luo, Tobias Kreiman, You Liang Tan, Dorsa Sadigh, Chelsea Finn, Sergey Levine RSS 2024 website / paper / code Laying the groundwork for a foundation model for robotics. |
|
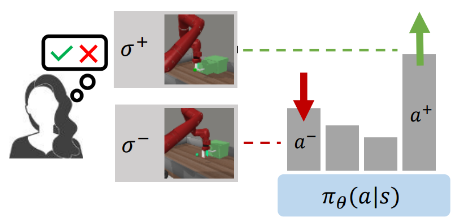
Joey Hejna, Rafael Rafailov*, Harshit Sikchi*, Chelsea Finn, Scott Niekum, W. Bradley Knox, Dorsa Sadigh ICLR 2024 paper / code Reduces Reinforcement Learning from Human Feedback to contrastive learning under the regret model of human preferences, which has recently been shown to be more accurate than the widely accepted reward model. Unlike many RLHF methods, CPL is fully off-policy and works on arbitrary MDPs. |
|
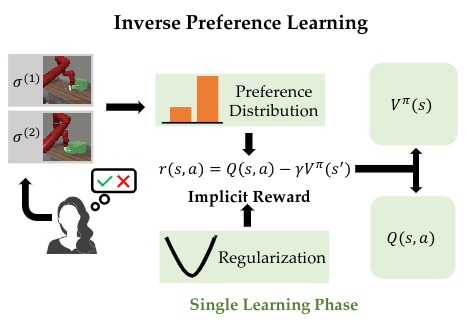
Joey Hejna, Dorsa Sadigh NeurIPS 2023 paper / code Approaches to preference-based RL typically work in two phases: first a reward function is learned, then it is maximized using a vanilla RL algorithm. We introduce the Inverse Preference Learning framework, where we directly learn a Q-function that models the user's preferences without explicitly learning a reward function. |
|
|
Joey Hejna, Jensen Gao, Dorsa Sadigh ICML 2023 paper / website / code We introduce DWSL, an algorithm for offline goal-conditioned reinforcement learning that uses only supervised objectives while still learning a constrained optimal policy. DWSL performs particularly well on high-dimensional image domains and seems robust to hyperparamters. |
|
|
Divyansh Garg*, Joey Hejna*, Matthieu Geist,Stefano Ermon *Equal Contribution ICLR 2023 (Notable, Top 5% of Submissions) paper/ website / code We introduce a novel framework for Q-learning that models the maximal soft-values without needing to sample from a policy and improves performance in online and offline RL settings. |
|
|
Joey Hejna, Dorsa Sadigh CoRL 2022 paper / website / code Pretraining preference models greatly reduces query-complexity, enabling humans to teach robots with a reasonable amount of feedback. |
|
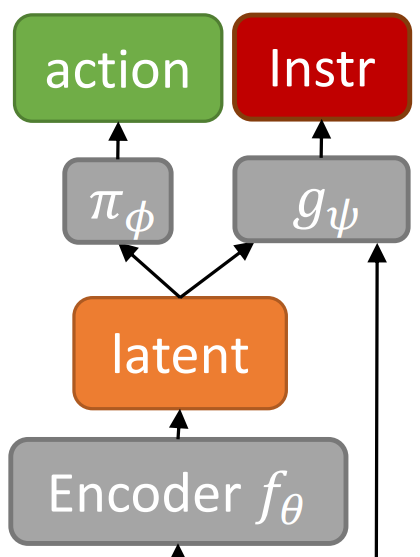
Joey Hejna, Pieter Abbeel, Lerrel Pinto AAAI 2023 paper / code We show that predicting instructions along with actions drastically improves performance in combinatorially complex long-horizon imitation settings. |

|
Donald J. Hejna III, Pieter Abbeel, Lerrel Pinto Accepted to ICLR 2021 paper / website / code Better robot strucutres hold the promise of better performance. We propose a new algorithm, TAME, that is able to evolve morphologies without any task specification. This is accomplished using an information theoretic objective that efficiently ranks morphologies based on their ability to explore and control their environment. |
|
|
Donald J. Hejna III, Pieter Abbeel, Lerrel Pinto Accepted to ICML 2020 paper / website / code / talk We propose transferring RL policies across agents using a hierarchical framework. Then, to remedy poor zero-shot transfer performance we introduce two additional imitation objectives. |
|
|

|
Donald J. Hejna III Open source project code A lightweight framework for general deep-learning research in pytorch. |

|
Donald J. Hejna III Open source project code A lightweight framework for general deep-learning research in pytorch. |

|
Donald J. Hejna III*, Ashwin Vangipuram*, Kara Liu* Course Project, CS 294-158 Unsupervised Learning, Spring 2020 paper We examine and compare three methods for explicitly disentangling learned latent representations in VAE models. |
|
|
|

|
Summer 2024 Working on the machine learning and robotics team. |

|
Summer 2019 Developed C++ systems for trading APIs and monitoring systems. Worked on optimizing memory usage of large model training. |

|
Summer 2018 blog post Worked on demo systems for Intel's OpenVino model optimization system in the AWS DeepLens. Explored systems for gradient based explanations of deep networks. |
|
|

|
NeurIPS 2023 Outstanding Reviewer, ICML 2024 Outstanding Reviewer, CoRL 2024, IEEE RA-L, RL-Brew at RLC 2024, ICRA 2025, ICML 2023, ICLR 2025 |

|
Course Assistant, CS 221: Artificial Intelligence, Autumn 2024 Head Course Assistant, CS 221: Artificial Intelligence, Autumn 2023 Teaching Assistant, EECS 127: Optimization Models, Fall 2020 Teaching Assistant, EECS 189: Machine Learning, Spring 2020 Teaching Assistant, CS 70: Discrete Math and Probability Theory, Fall 2019 |
|
Introductory ML Notes Deep Learning Workshop Reinforcement Learning Workshop |
|
Website source taken from here. |